What is Search Engine? Definition, Meaning, Working, & Examples
Published: 16 Aug 2025
Have you ever wondered how search engines provide you with such accurate results? Or, how do search engines quickly scan the entire web to find what you’re looking for?

I’m sure thousands of such questions about search engines are popping up in your mind. But, my dear readers, don’t you worry; in this article, we will learn about search engines in detail.
Let’s begin without further delay.
What is Search Engine?
A search engine is a software program that allows users to search for information on the internet. It scans and stores billions of web pages in its database, so when you type a query, it can quickly show you the most relevant results.

Search engines work in three main steps: crawling (finding pages), indexing (storing them), and ranking (showing results in order of relevance). Popular examples include Google, Bing, Yahoo, and DuckDuckGo. They make it easy to find websites, images, videos, and news within seconds.
Aim of Search Engine
By providing accurate results, search engines are well-positioned to increase their market share.
The goal of a search engine is to give users relevant and valuable information in response to their questions. This is done by crawling, indexing, and ranking websites and web pages based on their relevance and authority. The goal is to make it easy and quick for users to find the necessary information.
Search Engine Example
What we call a “search engine” is a piece of software designed specifically to conduct searches throughout the vast resources of the World Wide Web (www). Search engines are also known as answer engines.
Google is an example of a search engine. People use it to search for information on the internet by typing in keywords or phrases. Google displays a list of relevant web pages to that typed specific search query. Other examples of search engines include Bing, Yahoo, and DuckDuckGo.
In the next section, we will learn about the history and workings of search engines.
Search Engine History
Search engines are a crucial part of the web we know and love today. These digital gateways began in the 1990s, helping internet users traverse an ever-expanding ocean of information. In their short history, search engines have become indispensable tools for finding what you need on the world wide web!
- Archie was one of the first search engines. A group of students at Canada’s McGill University made it in 1990. Archie indexed the names of files kept on hidden FTP (File Transfer Protocol) sites, enabling users to search for specific files as compared to looking for specific keywords within the content of a website or web page.
- In 1993, the first true search engine, WebCrawler, was created. It indexed the file names and the contents of web pages. This made it possible for users to search for specific information online.
- In 1994, Yahoo! was founded as a directory of web pages organized by category. Instead of searching for websites of interest, users could simply browse through the directory.
- In 1996, two more search engines were launched: AltaVista and Excite. These search engines used advanced algorithms to index and rank web pages, making it easier for users to find relevant information.
- In 1998, Google was founded and quickly became the dominant search engine due to its ability to return relevant results to users’ queries. Using its advanced algorithm, PageRank. Google’s focus on relevance and simplicity set it apart from other search engines, leading to its widespread popularity.
Starting the search engine revolution, Google has remained king of searches for years. But there are other options out there – Bing, Yahoo and DuckDuckGo to name a few – bringing more choice into how you access information online. And with voice assistants becoming increasingly popular, asking questions aloud is also an easy way to find what you’re looking for quickly!
How Do Search Engines Work?
Search engines use web crawlers to systematically navigate hundreds of billions of pages to index the web. Search engine robots, or spiders, are another name for these types of web crawlers.
A search engine “crawls” the web by first downloading pages and then using the links on those pages to find other publicly available pages. Web content is stored in databases that can be accessed via search engines. Two major components make them up:
- Data indexing – A digital database containing website details.
- Search Algorithm(s) – Software(s) designed to compare search index entries and return matched pairs.
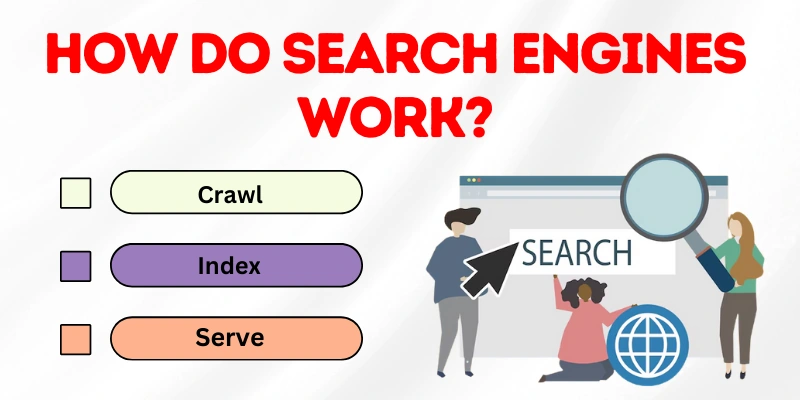
Now let us split our main query, “How do search engines work?” into five components that will help us understand the workings of search engines in more detail:
- Crawling
- Understanding
- Indexing
- Serving
- Ranking
1. What is Website Crawling?
Search engines are always on the move!
“Crawling” is the process by which search engines discover new and updated web pages. They do this by using software, such as “spiders,” “robots,” or “bots,” to follow links and inspect the source code and content of each page they visit. Crawling aims to identify relevant and high-quality content to add to the search engine’s index, allowing users to find it when they search easily.
The content being crawled can be a web page, an image, a video, a PDF, etc.; it is always found through links.
2. How Search Engines Understand Your Content?
Search engines are like a computer’s brain because they use many different ways to determine what words and content mean. Search engines use advanced methods like understanding, interpretation, and natural language processing to give users accurate results. These methods help search engines understand the keywords in users’ queries and check the content of web pages for relevance.
These techniques include:
- Natural Language Processing (NLP): To understand the context and meaning of words and phrases in the text.
- Latent Semantic Analysis (LSA): To identify the relationships between words and phrases in the content and determine the overall theme of the page.
- Keyword Analysis: To determine the relevance of the content to specific search terms and keywords.
- Link Analysis: To evaluate the quality and relevance of links pointing to and from the page.
- Meta Data Analysis: To gather information from the page’s meta tags and meta descriptions, such as title and description, to gain further insight into the content.
In summary, search engines use a combination of NLP, latent semantic analysis, keyword analysis, link analysis, and metadata analysis to understand the content of web pages and index them in a way that is relevant to users’ search queries.
3. How Search Engine Indexing Works?
Indexing in search engines means getting information about web pages, figuring out what it means, and storing it in the search engine’s index. This index is then used to give users search results based on what they typed in.
Crawling web pages, getting their content and metadata, and adding that information to a search engine’s index is what indexing is.
The more pages a search engine indexes, the better its search results will be. Indexing is an important part of how search engines work because it lets them quickly find the information a user seeks.
4. How Search Engine Results are Served?
The search engine serving procedure refers to how search engines deliver web pages to users in response to their search queries.
The search engine is designed to help people quickly and easily find information by analyzing various factors such as keywords, content relevance, link popularity, user engagement, etc. Results can include a variety of web pages, as well as photos, videos, or other types of content. It only serves accurate results so that users get the specific answers they are looking for in a timely manner.
5. How Search Engines Rank Websites?
Search engines’ ranking procedures decide which websites are the most relevant to a user’s search and in what order to display those websites to the user.

- Relevance: The page’s content must be relevant to the search query; otherwise, it cannot be ranked highly.
- Quality: Your content should be original, informative, and beneficial to the user. Search engines prioritize high-quality pages over low-quality content because they want to give their visitors the best results.
- Authority: Quantity and quality of inbound links to a page determine its authority. A page with several trustworthy and relevant links is considered an authoritative source and will rank higher.
- User experience: User experience is a broad word that includes various factors, such as website load speed, ease of navigation, mobile responsiveness, and more. A positive user experience can greatly boost a page’s ranking.
- Keyword usage: Keywords are important in determining a page’s relevance. However, search engines are now more intelligent, and keyword stuffing (the excessive use of keywords) can negatively affect a page’s rating.
Search engine algorithms are always changing, so it’s essential for websites to stay ahead of the curve. Optimizing your site involves keeping track of search engine trends and ensuring you’re continually improving page rankings by providing high-quality content with an exceptional user experience.
What Happens When Search is Performed?
When you perform a search query, complex algorithms quickly scan vast databases and indexes of information to find documents or webpages that best match your request.
The results are then carefully ranked in order of relevancy for the most helpful outcome – so whether it be websites, images, or videos, finding what you need is easy!

All searches start on either a local computer network or out on the internet, with servers working hard behind the scenes delivering up only useful content related to your needs.
Here are some steps a search engine takes after search performance:
- User submits a search query: A search query is typed into the search bar, and the user clicks the “search” button.
- Search engine processes the query: The search engine uses natural language processing (NLP) techniques to figure out what the user wants and then uses its algorithms to find the most relevant pages in its index that match the user’s request.
- Search engine returns results: The search engine delivers a list of websites in the order in which they correspond to the user’s query. The search results may contain web pages, photos, videos, and other material forms.
- User reviews the results: The user reviews the search results and clicks on one or more links to visit the corresponding web pages.
- Search engine tracks the user’s activity: The search engine tracks the user’s activity, such as which results were clicked, how long the user spent on each page, and which pages were returned in the search results. This information improves the search engine’s algorithms and provides more relevant future results.
- Search engine also personalizes the results: The search engine considers the user’s location, search history, cookies, and other personalization factors to return more relevant results and improve the user experience.
Why Certain Pages Rank Higher in Search Engines?
The most critical factor determining why some pages show up higher in the search results than others is the quality of the content. Search engines prioritize content that is relevant to the query and of high quality.
Search engines use their advanced algorithms to determine whether a web page is relevant and trustworthy or not. These algorithms consider the page’s content, keyword usage, the number and quality of links, the user experience, and the speed at which the page loads.
More important, useful, and authoritative pages are listed higher in search results. The exact factors taken into account and how much weight is given to each factor can vary from search engine to search engine.
Common Reasons a Page is Not Indexed by Search Engine
There are several reasons why a search engine might not index a page:

- Blocked by robots.txt: The page may have been blocked by the robots.txt file of the website, which instructs search engine crawlers not to index particular pages or sections of the site.
- No incoming links: A page must have incoming links to be discovered by the search engine’s crawlers.
- Duplicate content: If the page has duplicate content, it may be considered low-quality and not indexed by the search engine.
- Low-quality content: If the page has low-quality content, such as thin or shallow content, it may not be indexed by the search engine.
- Technical issues: Technical issues such as broken links, 404 errors, and server errors can prevent a page from being indexed by the search engine.
- Limited crawling budget: Search engines allocate a limited amount of resources to crawling; if a website has too many low-quality pages, it may be unable to crawl all of them.
- New website: If the website is new, it may take some time for the search engine to discover and index its pages.
- No sitemap: If a website doesn’t have a sitemap can make it difficult for search engines to discover new pages and index them.
Differences Between Search Engines
Till now, we have learned what search engines are and how a search engine works. Moreover, remember that each search engine has a different index size, algorithms, personalization, search features, ads, and specialized search capabilities. Let us learn these major differences in a bit of detail.
- Index size: Different search engines have different index sizes, meaning that they have indexed different numbers of web pages. Google has the most extensive index, followed by Bing and Yahoo.
- Algorithms: Each search engine has its own set of algorithms and ranking factors that it uses to determine the relevance and importance of web pages. While all search engines consider factors such as keywords and backlinks, the weight and importance of each factor may vary.
- Personalization: Search engines also have different levels of personalization; some search engines like Google, Bing, and Yahoo use the user’s location, search history, cookies, and other personalization factors to return more relevant results and improve the user experience.
- Search features: Search engines also offer different features such as filters, operators, and autocomplete to help users refine their search queries and find the most relevant results.
- Ads: Some search engines like Google, Bing, and Yahoo also serve ads along with the search results, which are targeted based on the user’s location, browsing history, and other personalization factors.
- Specialized search: Some search engines like Google Scholar, Bing Academic, and other specialized search engines are designed to search for academic, scientific, and other specialized content.
Conclusion
So guys, in this guide we have covered what is search engine in detail — from how it works to how results are served and ranked. This is a general guide on how search engines work, and these rules apply to almost all of them. But remember, every search engine also uses its own unique parameters.
From the top 10 search engines available today, Google is considered the most powerful one. I hope your queries about the search engine working have been cleared, but still, if there is any confusion, then drop a comment below. I will be helping you here.
FAQs about Search Engines
Here are some of the most frequently asked-about search engines.
You can use the search operator “site:” to search a specific website using a search engine. For example, if you want to search for “example” on the website “www.example.com”, you would enter the following into the search engine: “example site:www.example.com”. This will return search results from the website “www.example.com”, including the keyword “example”.
A search engine works in five steps:
- Crawl
- Understand
- Index
- Serve
- Rank
Some of the best search engines are:
- Baidu
- Bing
- Yandex
- DuckDuckGo
Web search refers to finding information on the internet using a search engine such as Google, Bing, or Yahoo. The user enters the word or phrase for which they are looking for information into the search engine’s search bar.
Here are the benefits of search engines:
- Convenience
- Speed
- Relevance
- Variety
- Personalization
Here are some cons of search engines:
- Privacy concerns
- Spread of false information
- Bias
- Advertising
- Addiction and overuse
To create your own search engine software, you must follow these basic steps:
- Crawling: Develop a web crawler that can automatically visit web pages.
- Indexing: Create an index that stores the information gathered by the crawler.
- Searching: Build a search algorithm that compares a user’s query with the indexed pages and returns relevant results.
- Ranking: Implement a ranking algorithm to sort the results based on relevance.
- Serving: Build a system that can serve the search results to users quickly and efficiently using a web server.
To use a search engine, such as Google, Bing, or Yahoo, follow these steps:
- Utilize a web browser to visit the search engine’s webpage.
- In the search bar at the top of the page, enter the keywords or phrases you wish to find.
- Press “Enter” or click “Search” to perform a search.
- The search engine will provide relevant web pages responding to your query.
A search engine finds results by using a complex process called web crawling. This process involves sending out automated programs, called crawlers or spiders, to scan and index the content of websites.
Google’s algorithm is a complex and ever-evolving system used to determine the relevance and authority of websites and pages in response to a user’s search query. The algorithm uses a variety of factors to rank and order search results, and the specific details of how Google does this are not publicly disclosed.
There are eight types of search engines:
- General search engines
- Vertical search engines
- Metasearch engines
- Hybrid search engines
- Mobile search engines
- Enterprise search engines
- Deep web search engines
- Voice-based search engines
- Google handles about 40,000 search requests every second. This means that there are 3.5 billion daily and 1.2 trillion searches yearly. 57% of all search traffic comes from phones and tablets.
- 77% of people who use Google search do so at least three times a day.






- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
