What is Robots.txt File & Why It’s Important for Every Website
Published: 9 Oct 2025
Ever heard about a small file that decides what search engines can see on your site? Yes, that’s the robots.txt file. Most people never notice it, but it quietly controls what gets shown on Google and what stays hidden. Sounds tricky, right? Don’t worry.
In this guide, we’ll break down everything about what is robots.txt file, how it works, and why it matters for your website’s SEO.
So, let’s start.
What is Robots.txt File?
The robots.txt file is a simple text file that tells search engines which pages or folders they can open and which they should skip. It sits in the root directory of your website, for example, www.yourwebsite.com/robots.txt.
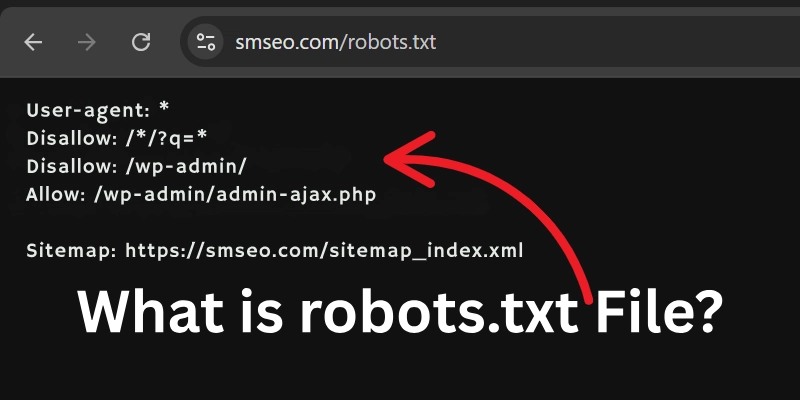
This file helps you control how search engines interact with your site. It can stop them from crawling admin areas, test pages, or private folders. It’s a quick way to guide crawlers and protect sensitive content.
Here’s a simple example:
User-agent: *
Disallow: /private/
Allow: /
Explanation:
- The User-agent: * means the rule applies to all search engines.
- The Disallow: /private/ tells them not to enter the “private” folder.
- The Allow: / opens access to the rest of your website.
This keeps private data safe while letting Google index your main pages.
How Does Robots.txt File Work?
When a search engine visits your website, it first checks the robots.txt file before doing anything else. Think of it as a “do’s and don’ts” list for crawlers.
If the file allows a page, the crawler visits and indexes it. If the file blocks it, the crawler skips that part. This helps you control what appears in search results.
Example:
- If your file says Disallow: /admin/, crawlers won’t open that folder.
- If it says Allow: /blog/, they’ll visit and index all your blog posts.
In short, the robots.txt file guides crawlers where to go and what to leave alone.
Why Is Robots.txt File Important for SEO?
A robots.txt file helps search engines crawl your site the right way. It guides bots on what to check and what to skip.
If search engines waste time crawling useless pages, they may miss your main content. That’s why a clean robots.txt improves crawl efficiency and SEO health.
Key reasons it matters:
- Helps search engines crawl your website properly.
- Guides bots on what to check and what to skip.
- Saves crawl budget for your main pages.
- Prevents duplicate or thin pages from being indexed.
- Hides private or admin areas from search results.
- Keeps your sitemap easy to find for crawlers.
- Blocks bad or unwanted bots from your site.
- Avoids server overload from too many crawl requests.
- Improves overall site visibility and SEO performance.
Robots.txt Parameters and Directives
A robots.txt file uses specific commands to control how search engines crawl your website. Below are all the parameters and symbols:
- # (comment)
- User-agent
- Disallow
- Allow
- Empty / Null directive
- / (slash)
- * (asterisk)
- $ (dollar)
- ? (question mark)
- Sitemap
- Crawl-delay
- Grouping / User-agent groups
- Path rules and case sensitivity
- File encoding and size limit
Here are the detailed explanations, examples, and tips for each.
1. Comment (#)
It’s used to write notes for humans inside the robots.txt file. Search engines ignore everything after the # symbol. You can use it to explain what a rule means or why it’s added; it helps others understand your file easily.
Example:
# Block the admin area
Disallow: /admin/
Tip: Use comments often to keep your file clear and organized.
2. User-agent
It tells which search engine bot the rule applies to. Each bot has its own name, like Googlebot, Bingbot, or AhrefsBot. You can also use an asterisk (*) to apply rules to all bots at once.
Example:
User-agent: Googlebot
Disallow: /test/
Tip: You can have different user-agent groups for different bots.
3. Disallow
It blocks search engines from crawling a specific page or folder. This keeps unwanted or private sections out of the crawler’s reach. It doesn’t delete pages from Google; it just tells bots not to read them.
Example:
User-agent: *
Disallow: /private/
Tip: Always start the path with a / and be careful with capitalization.
4. Allow
It gives search engines permission to access a specific page or file. You use it when you want to open one file inside a blocked folder. It helps when you want bots to load your CSS or JavaScript while blocking the rest.
Example:
User-agent: *
Disallow: /admin/
Allow: /admin/login.html
Tip: The more specific rule (longer path) usually wins if two rules conflict.
5. Empty or Null Directive
If the line after a directive is empty, it means there’s no restriction. Bots are free to crawl all pages on the site. This is useful when you want to make your entire website open to all crawlers.
Example:
User-agent: *
Disallow:
Tip: This is the same as having no robots.txt file at all.
6. Slash (/)
The slash represents the root directory of your website. When you block /, it means the entire site is off-limits for bots. When you allow /, all pages and folders are open for crawling.
Example:
Disallow: /
Tip: Use this only when your site is under maintenance or private.
7. Asterisk (*)
It works as a wildcard symbol that matches any set of characters. It can apply to all bots or any part of a URL path. This helps you block or allow multiple similar pages at once.
Example:
Disallow: /temp/*
Tip: Use carefully, one wrong wildcard can block important pages.
8. Dollar Sign ($)
It marks the end of a URL pattern. You use it to match only URLs that end with a specific word or extension. It’s great for blocking file types like PDFs, images, or documents.
Example:
Disallow: /*.pdf$
Tip: Use it when you want to block certain file formats from crawling.
9. Question Mark (?)
It helps target URLs that have query parameters like filters or searches. These often create duplicate pages or messy URLs. Blocking them keeps your site clean and helps prevent index bloat.
Example:
Disallow: /*?search=
Tip: Use this to stop bots from crawling endless filter and sort URLs.
10. Sitemap
It tells search engines where your sitemap file is located. A sitemap helps bots find all your pages quickly. This line should include the full URL and can appear anywhere in the file.
Example:
Sitemap: https://example.com/sitemap.xml
Tip: You can list multiple sitemap lines if you have more than one.
11. Crawl-delay
It asks a bot to wait for a few seconds between requests. This helps reduce server load when many pages are being crawled. Google ignores this directive, but some other bots still respect it.
Example:
User-agent: Bingbot
Crawl-delay: 10
Tip: Use only when bots overload your site with too many hits.
12. Grouping Rules
You can group rules under each user-agent. Each group starts with a User-agent line followed by its own Allow and Disallow lines. Bots read only the group made for them.
Example:
User-agent: Googlebot
Disallow: /test/
User-agent: *
Disallow: /private/
Tip: More specific groups override the general ones.
13. Path Rules and Case Sensitivity
Paths in robots.txt are case-sensitive and must match your actual folder names. /Admin/ and /admin/ are not the same. Always use correct casing and start paths with a forward slash.
Example:
Disallow: /Admin/
Tip: Double-check your URLs to avoid missing or wrong matches.
14. File Encoding and Size
The robots.txt file must be in plain text and saved in UTF-8 format. Search engines read only up to a certain size limit, so large files may get cut off. Keeping it clean and light helps bots read it faster.
Example:
robots.txt file encoded in UTF-8
Tip: Avoid fancy formatting, HTML tags, or special characters.
Learn Robots.txt with Practical Examples
Let’s make it easy; here are simple robots.txt examples to understand how crawling rules work. Each one shows what search engines can or cannot do on your site.

Example 1: Allow All Crawling
User-agent: *
Allow:What It Does:
- The asterisk (*) means this rule applies to all search engine bots.
- The Allow command (empty here) tells bots that they can crawl every part of the site.
- This setup gives full freedom to all crawlers; nothing is blocked or restricted.
- Ideal for open, public websites where you want all pages indexed.
Example 2: Allow Root Directory
User-agent: *
Allow: /What It Does:
- The asterisk (*) again applies to all bots.
- The Allow: / line means bots can access everything under the root folder (your main site).
- Similar to Example 1, but it explicitly gives permission to crawl the entire site.
- Best used to make sure crawlers know they’re allowed everywhere on your domain.
Example 3: Disallow None
User-agent: *
Disallow:What It Does:
- The Disallow command is empty, which means nothing is blocked.
- Bots can crawl every page freely, just like the “Allow All” example.
- It’s a clear way to tell search engines that you have no restrictions.
- Good for SEO when you want full site visibility in search results.
Example 4: Disallow All
User-agent: *
Disallow: /What It Does:
- The Disallow: / rule blocks crawlers from accessing any page on the site.
- It means “don’t crawl anything.”
- Search engines will still see the domain but can’t index its content.
- Commonly used for staging, testing, or private websites.
Sample Robots.txt Files with Explanation (DgAps Examples)
Now let’s move to practical robots.txt setups from dgaps.com and see what each line means.
Sample No. 1 – Googlebot Only
# This is the robots file for dgaps.com
User-agent: Googlebot
Disallow:
Sitemap: https://dgaps.com/sitemap.xmlLine-by-line breakdown:
- # is a comment line for human notes (ignored by bots).
- User-agent: Googlebot targets only Google’s crawler.
- Disallow: is empty, meaning Googlebot can crawl all pages freely.
- Sitemap: tells Google where to find your sitemap for better indexing.
Effect on Crawling:
- Googlebot can explore the whole site.
- Other crawlers follow their own rules (since they aren’t mentioned).
- Ideal when you only want to optimize crawling for Google.
Sample No. 2 – Googlebot + All Other Crawlers
# This is the robots file for dgaps.com
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
Sitemap: https://dgaps.com/sitemap.xmlLine-by-line breakdown:
- The first section gives Googlebot full access.
- The second section applies to all other crawlers (*).
- Disallow: / tells them not to crawl any page.
- The sitemap location helps Googlebot find all listed URLs.
Effect on Crawling:
- Googlebot can index all pages.
- Other bots (like Bing or Yahoo) are fully blocked.
- Useful when you want only Google to crawl and save server resources.
Sample No. 3 – Blocking Query Parameters (?page= and ?search=)
# This is the robots file for dgaps.com
User-agent: *
Disallow: /*?page=*
Disallow: /*?search=*
Sitemap: https://dgaps.com/sitemap.xmlLine-by-line breakdown:
- User-agent: * means all bots follow this rule.
- Disallow: /*?page=* stops crawling of any page with ?page= in its URL.
- Disallow: /*?search=* blocks internal search result pages.
- The sitemap shows where crawlers can safely explore indexed pages.
Effect on Crawling:
- Prevents duplicate or unnecessary pages from being indexed.
- Saves crawl budget by skipping repetitive URLs.
- Keeps search results and pagination pages out of Google’s index.
Each robots.txt file works differently:
- Example files teach the basics of crawling permissions.
- DgAps samples show how real-world websites control access and improve SEO.
Together, they help you understand how to make your own robots.txt file: safe, clean, and search-friendly.
How to Create a Robots.txt File (Step-by-Step)
Follow these simple steps. Keep each step short and do it carefully.
Plan what to block and allow. Decide which folders or pages you want hidden. Note any pages you need crawled. Write a short list first.
Open a plain text editor. Use Notepad, TextEdit (plain text), or VS Code. Do not use a word processor. Save the file as robots.txt.
Save with UTF-8 encoding and no BOM. In Windows Notepad choose Save As and set Encoding to UTF-8. In TextEdit set Format to Make Plain Text and save as UTF-8.
Write your rules. Use User-agent, Disallow, Allow, and Sitemap lines. Start each path with /. Keep rules clear and short. Example:
User-agent: *
Disallow: /private/
Sitemap: https://yourdomain.com/sitemap.xmlCheck syntax before upload. Make sure paths start with /. Do not add HTML. Remove extra spaces. Use # for comments only.
Upload the file to your site root. Put robots.txt in the site root folder (public_html, www, or the document root). The file must be reachable at https://yourdomain.com/robots.txt.
Use common upload methods:
- In cPanel: open File Manager, go to public_html, upload the file.
- With FTP/SFTP: upload to the document root (example: /public_html/).
- In WordPress: use an SEO plugin file editor or a file manager plugin to place it at site root.
Set file permissions to readable. Use permission 644 so the webserver can read the file. Do not make it executable.
Test in a browser first. Open https://yourdomain.com/robots.txt. You should see your file and rules. If you get an error, re-upload.
Test with Google Search Console. Use the robots.txt tester to check specific URLs. Run tests as Googlebot to confirm rules work. Or you can use any third-party online testers if needed.
Validate HTTP response. Make sure the robots.txt URL returns status 200. If it returns 4xx or 5xx, crawlers may ignore the file or treat it as missing.
Monitor logs and search console. Watch server logs for blocked or 404 requests. Check Coverage and Crawl stats in Search Console for crawl issues.
Update carefully and keep version history. Save old copies before changes. Small mistakes can block important pages. Keep comments in the file to explain changes.
Key Rules and Precautions to Remember
Keep these simple rules in mind while creating or editing your robots.txt file:

- Always place it in the root directory. Search engines can only find it at https://yourwebsite.com/robots.txt.
- The filename is case-sensitive. Write it exactly as robots.txt, not Robots.txt or ROBOTS.TXT.
- Do not include private URLs. Anyone can open your robots.txt file, so never list secret or admin pages there.
- Avoid blocking everything by mistake. Using Disallow: / means search engines cannot crawl any page.
- Use Allow and Disallow correctly. Wrong use can block your entire site.
Example clarifications:
- Allow: + Disallow: / → everything blocked.
- Allow: / + Disallow: → everything allowed.
A small typo or wrong symbol can affect your entire site’s visibility, so check twice before saving.
Common Robots.txt Mistakes to Avoid
Many beginners make small but serious mistakes. Here are the most common ones:
- Blocking important CSS or JavaScript files: this can harm your site’s appearance on Google.
- Forgetting to add your sitemap link at the end.
- Confusing “noindex” (used in meta tags) with “disallow” (used in robots.txt).
- Uploading the file in a subfolder instead of the main root directory.
- Using uppercase letters in the filename.
Each of these can stop Google from reading or understanding your website properly.
Robots.txt vs Meta Robots Tag
Both control how search engines handle your content, but they work in different ways:
| Feature | Robots.txt | Meta Robots Tag |
| Main purpose | Controls crawling (which pages bots visit) | Controls indexing (which pages appear in search) |
| Location | In the root directory | Inside the HTML head of a webpage |
| Best used for | Hiding folders or files | Controlling visibility of individual pages |
| Example use | Stop bots from entering /private/ | Stop bots from indexing a page but still allow crawling |
When to use:
- Use robots.txt to control access to entire sections or file types.
- Use meta robots tag to manage how single pages appear in search results.
Conclusion
In this guide, we have covered what is robots.txt file in simple and clear steps. You now know how it works, how to create one, and how to avoid common mistakes.
As an experienced site owner in website optimization, I’ve seen how a small file like this can make a big difference. You can allow and disallow search bots with very small parameters, so please check out the things correctly here.
If you’re new, take a few minutes to check your own robots.txt file today; it will help you better understand this small but important file for managing your site. So now, let’s move to the FAQs section for quick answers to the most common questions about robots.txt files.
FAQs
Here are some of the most commonly asked questions related to robots.txt and SEO:
Open the robots.txt tester in Google Search Console and see which rule is blocking the URL. Then edit your robots.txt file to allow that path (remove or change Disallow). After the update, resubmit or request indexing so Google rechecks the page.
Go to https://yourdomain.com/robots.txt in your web browser. If the file is correctly placed at root and public, you will see its content. If you see an error (404 or access denied), it’s not accessible or not in the right location.
No! If you have nothing to block, you can skip having a robots.txt. But having one helps you control how crawlers behave and protect private parts of your site. It also lets you point bots to your sitemap for better crawling.
Yes! Robots.txt is just a standard web file with instructions for crawlers. It doesn’t break any laws, and you are free to configure it as you wish. Because it is public, any user (or bot) can see it and read its rules.
Yes, using Disallow: / for User-agent: * will block all pages from being crawled. Search engines then can’t access any content of your site. But even then, some URLs may show in results without content (if they are linked elsewhere).
If a site has no robots.txt, crawlers assume they may crawl all pages freely. Your site will still get crawled unless you block it elsewhere. It’s not usually a problem, but you lose control over which areas should or shouldn’t be crawled.





- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
